Machine Learning dans le monde de l’assurance cas d’étude | R & SVM
Résumé
La compétition Safe Driver Prediction, organisée par Kaggle, invite à créer un modèle qui prédit la probabilité qu’un conducteur fasse une demande de réclamation d’assurance automobile dans l’année subséquente. Nous avons décidé de nous prêter au jeu et de s’attaquer au défi, avec la technique Support Vector Machines, et le Stochastic Descent Gradient comme armes de prédilection. Cette technique robuste date des années soixante, mais a perdu en popularité au profit d’autres approches telles que les réseaux neuronaux ou la forêt aléatoire (random forest). Découvrez notre méthodologie et le fruit de notre travail à travers cet article.
CONTEXTE
Porto Seguro, importante compagnie d’assurance au Brésil, cherche à adopter un nouveau modèle de calcul de l’assurance automobile. L’objectif est de pallier aux inexactitudes courantes des prévisions de réclamations, qui imposent des primes d’assurance trop élevées aux bons conducteurs et trop peu élevées aux mauvais conducteurs.
Kaggle a donc lancé une compétition qui invite tous et chacun à soumettre un modèle qui permette de prédire la probabilité qu’un conducteur fasse une réclamation d’assurance dans l’année.
INTRODUCTION AU JEU DE DONNÉES
Voici l’approche adoptée face au jeu de données, pour répondre au défi de Kaggle :
Les données présentées par la compagnie d’assurance contiennent des annotations spécifiques représentant différents groupes et sont marquées comme telles dans les noms de caractéristiques (ind, reg, car, calc). Les noms de variables incluent le bin en suffixe pour indiquer les variables binaires et cat pour indiquer les variables catégorielles. Les autres caractéristiques sans ces suffixes sont soit continues ou bien ordinales.
Les valeurs de -1 indiquent que l’entité manquait à l’observation. Les colonnes cibles, elles, indiquent si une réclamation a été déposée ou non pour ce preneur d’assurance.
[sourcecode language= »r »]
### Importé un jeu de données avec le package READR permet
### d’importer rapidement un large ou moyen jeu de données
data_train <- read_csv("Insurrancedata/train.csv", col_types = cols())
[/sourcecode]
EXPLORATION DU JEU DE DONNÉES
[sourcecode language= »r »]
dim_data_train <- dim(data_train)
print(paste0("Le jeu de données contient ", dim_data_train[1],
" observations pour ", dim_data_train[2], " variables"))
[/sourcecode]
En observant les variables, qui représentent les différentes caractéristiques des clients, on remarque d’après la distribution et le type de variables qu’il pourrait s’agir de caractéristiques sociodémographiques, mais aussi de caractéristiques en lien avec le monde de l’assurance. Il est important de garder en tête que les données utilisées dans ce cas-ci sont des données anonymisées.
En savoir plus sur les données de nature anonymisées
[sourcecode language= »r »]
sapply(data_train, class)
[/sourcecode]
La variable « target », soit la réclamation ou non d’un individu dans l’année, est une variable binaire dont nous allons rapidement étudier la distribution :
[sourcecode language= »r »]
dist_target <- table(data_train$target)
perc_claim <- paste0(round((dist_target[2]/dist_target[1]) *
100, 2), "%", " des clients dans le jeu de données ont fait une réclamation.")
ggplot2::ggplot(data = data_train, aes(x = as.factor(target))) +
geom_bar(fill = "#84a5a3") + labs(title = "Distribution de la class Target",
x = "Réclamation", y = "Fréquence", subtitle = perc_claim) +
scale_y_continuous(labels = scales::comma)
[/sourcecode]
Distribution de la class Target
3.78 % des clients dans le jeu de données ont fait une réclamation.
On note que le constat est sans appel et la variable « target » est débalancée. Ce cas précis de jeu de données débalancé est très récurrent dans le monde de l’assurance, de la fraude bancaire et dans le secteur médical pour la détection de maladies rares. Il existe effectivement plusieurs approches pour débalancer le jeu de données, tels que le sous-échantillonnage et le sur-échantillonnage (comme le SMOTE).
TRANSFORMATION DES DONNÉES
La transformation des données est nécessaire pour obtenir un résultat tangible et éviter tout biais potentiel durant la modélisation. L’analyse exploratoire et l’introduction nous ont permis de constater la présence de variables catégoriques, continues et binaires, ainsi que de valeurs manquantes.
« Categorial One Hot Encoding »
Nous transformons ensuite les variables catégoriques en plusieurs variables binaires afin de faciliter la modélisation. À noter que nous gardons les valeurs manquantes dans les variables catégoriques afin de les inscrire dans de nouvelles variables binaires. Nous procédons ainsi puisque les données sont anonymisées et que la suppression d’une donnée manquante dans ce contexte est risquée et pourrait engendrer une perte d’information.
Pour plus d’informations sur les méthodes de transformation des variables catégoriques, consultez le lien suivant :
[sourcecode language= »r »]
vars_cat <- names(data_train)[grepl("_cat$", names(data_train))]
data_train <- data_train %>% mutate_at(.vars = vars_cat, .funs = as.factor)
data_train <- model.matrix(~. – 1, data = data_train)
data_train <- as.data.frame(data_train)
[/sourcecode]
Normalisation des données et « Feature Engineering »
Afin de continuer notre transformation des données, nous aurions pu mener une analyse de corrélation entre les variables, puis faire une réduction de dimension. Cependant, nous prenons un raccourci très efficace que l’on appelle « Analyse des composantes principales » (Principal Component Analysis). L’analyse des composantes principales (ACP) est une procédure statistique qui utilise une transformation orthogonale pour convertir un ensemble d’observations de variables éventuellement corrélées en un ensemble de valeurs de variables linéairement non corrélées, appelées « composantes principales » (ou parfois « principaux modes de variation »). Cet ensemble est utilisé pour expliquer la structure de variance-covariance d’un groupe de variables à travers des combinaisons linéaires. Il est souvent utilisé comme technique de réduction de dimensionnalité. Ainsi, le résultat obtenu est un nombre de nouvelles variables normalisées et non corrélées, prêtes à être modélisées.
[sourcecode language= »r »]
res <- stats::prcomp(data_train[, c(-1, -2)], center = TRUE,
scale = TRUE)
data_train_transformed <- data.frame(target = data_train$target,
res$x)
[/sourcecode]
MODÉLISATION
On note, à travers l’exploration primaire et selon nature du problème, qu’il s’agit d’un exercice de classification binaire. Pour modéliser des données d’un problème de classification binaire, plusieurs modèles sont envisageables, tels que : arbres de décision, forêt aléatoire, réseau bayésien, vecteurs de support machine, réseaux neuronaux, régression logistique. Dans le contexte d’un jeu de données débalancé comme celui en vigueur, il est nécessaire de bien connaître les handicaps de chaque modèle.
La régression logistique considère la cible positive (claim == 1), comme du bruit (c’est-à-dire négligeable) et n’est donc pas adaptée pour détecter les clients qui feront des réclamation l’an prochain. À l’opposé, les modèle du type forêt aléatoire ou supports de vecteurs répondent mieux aux objectifs de l’exercice. Dans notre cas, nous avons décidé d’opter pour les supports de vecteur.
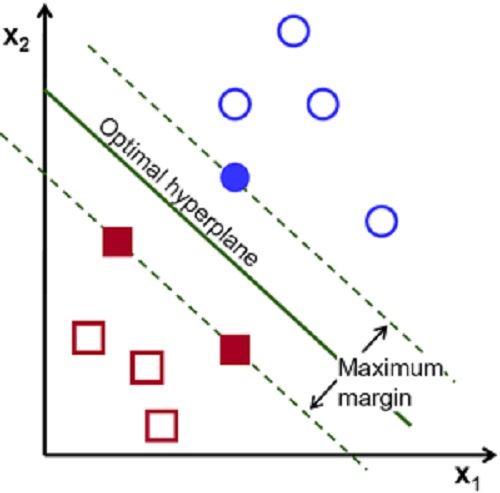
Support de vecteur machine – svm et temps de ré-solution
Malgré sa faible sensibilité au jeu de données débalancé, le modèle de supports de vecteur peut présenter un temps de résolution très important car la complexité algorithmique du SVM se situe entre nˆ2 et nˆ3, ce qui se traduit en un temps de calcul et de formation des données de plus de 10 heures sur un cluster cloud optimisé.
Afin de pallier à ce problème, il existe différentes techniques permettant de réduire le temps de calcul d’un SVM, dont le calcul parallèle, l’utilisation des learners et lightSVM. Nous allons utiliser le solveur Pegasos pour les fins de la compétition, mais notez qu’il en existe plusieurs autres, comme Stochastic Descent Sub-Gradient, Stochastic Descent Gradient et Perceptron. Pegasos nous permettra de résoudre le problème d’optimisation posé par les SVM et ainsi obtenir un résultat dans un délai rapide, car la dimensionnalité du jeu de données n’a pas d’impact sur le temps de résolution.
Pour plus d’information sur les SVM et sur les Stochastic Descent Sub-Gradient, consultez l’article suivant :
https://lingpipe-blog.com/2009/04/08/convergence-relative-sgd-pegasos-liblinear-svmlight-svmper/
Pegasos SVM : Sofia ML
Pour la modélisation, nous allons utiliser la librairie Sofia ML. Afin d’installer la librairie, une légère modification est nécessaire; celle-ci nous permettra l’utilisation d’un module dépréciatif de Rcpp.
[sourcecode language= »r »]
.Deprecated("loadModule", package = "RSofia", old = "loadRcppModules")
library(RSofia)
# pour faire les parallèles et le loop des fold
library(doParallel)
library(foreach)
gc()
[/sourcecode]
Validation et test du modèle par : validation croisée
La validation croisée permet d’échantillonner notre jeu de données pour pouvoir le mettre au défi par validation ou par test. Pour ce faire, nous avons sélectionné deux méthodes de validation croisées.
La première est le partitionnement des données : nous avons opté pour un ratio de 70/30 pour la formation et le test. Ce type de démarche est essentiel pour permettre de tester la performance de notre modèle et vérifier qu’il n’existe aucun biais.
La deuxième est le « K-Fold validation », qui nous permet de valider le modèle plusieurs fois durant l’étape de modélisation, et cela, par échantillonnage :
« [. . . ] divise l’échantillon original en k échantillons, puis on sélectionne un des k échantillons comme ensemble de validation et les (k-1) autres échantillons constitueront l’ensemble d’apprentissage. On calcule comme dans la première méthode le score de performance. Puis, on répète l’opération en sélectionnant un autre échantillon de validation parmi les (k-1) échantillons qui n’ont pas encore été utilisés pour la validation du modèle. », selon Wikipedia.
Nous avons sélectionné 10 folds pour la validation, qui occuperont chacun un core de notre machine, afin de donner lieu à un calcul parallèle pour accélérer les choses.
NB : En réalité, trois échantillonnages auront lieu durant la résolution de l’optimum des SVM par le solveur Pegasos : le partitionnement (formation-test), la validation K-Fold et l’échantillonnage par itération. On pourrait penser que cela représente beaucoup d’échantillonnage. Toutefois, dans le contexte de la compétition Kaggle, et contrairement aux autres modèles n’ayant pas été validés et testés plusieurs fois, notre triple échantillonnage nous permet d’obtenir un score de gini public (public leaderboard), similaire à celui qui sera privé (private leaderboard).
[sourcecode language= »r »]
### Échantilllonnage à 70/30
split_size <- floor(0.7 * nrow(data_train_transformed))
set.seed(122)
train_index <- caret::createDataPartition(data_train_transformed$target,
p = 0.7, list = FALSE, times = 1)
train_70 <- data_train_transformed[train_index, ]
test_30 <- data_train_transformed[-train_index, ]
## K FOLD VALIDATION Préparation Définir le nombre cores pour
## le k fold validation
registerDoParallel(cores = 10)
### Identifier les folds dans le jeu de données/ Nb de
### cores==Nb de fold — Ici 10 cores pour 10 fold
set.seed(2017)
train_70$fold <- caret::createFolds(train_70$target, k = 10,
list = FALSE)
### Pegasos et SVM avec K-FOLD VALIDATION
output_cv <- foreach::foreach(j = 1:max(train_70$fold), .combine = rbind,
.inorder = TRUE) %dopar% {
cv_train <- train_70[train_70$fold != j, ]
cv_test <- train_70[train_70$fold == j, ]
### Sofia ml package pour 10 millions d’itération, un lambda à
### 0.01 et un échantillonnage d’itération pour optimiser la
### AUC ROC.
svm_pegasos <- RSofia::sofia(target ~ ., data = cv_train,
random_seed = 201, lambda = 0.01, iterations = 1e+07,
learner_type = "pegasos", eta_type = "pegasos", loop_type = "roc",
training_objective = FALSE, verbose = FALSE)
svm_pegasos_validation <- predict.sofia(svm_pegasos, cv_test,
prediction_type = "logistic")
gini <- NormalizedGini(svm_pegasos_validation, cv_test$target)
result <- data.frame(y = cv_test$target, prob = svm_pegasos_validation)
list(svm_pegasos = svm_pegasos, gini = gini, result = result)
}
gc()
[/sourcecode]
Après avoir validé notre modèle sur les 10 folds, il est temps de calculer le pointage de gini pour l’étape de validation, puis celui pour l’étape de test. Le tout, sans oublier de vérifier notre matrice de confusion pour identifier tout biais dans le modèle.
[sourcecode language= »r »]
paste0(mean(output_cv$gini), "Gini coeff moyen durant la validation avec 10 folds")
svm_pegasos_test <- predict.sofia(output_cv$svm_pegasos, test_30, prediction_type = "logistic")
paste0(NormalizedGini(svm_pegasos_test, test_30$target), "Gini coeff pour la phase test")
svm_pegasos_test_threshold <- ifelse(svm_pegasos_test < 0.6, 0, 1)
ConfusionMatrix(svm_pegasos_test_threshold, test_30$target)
[/sourcecode]
LE CODE SOURCE
[sourcecode language= »r »]
### Importé un jeu de données avec le package READR permet
### d’importer rapidement un large ou moyen jeu de données
data_train <- read_csv("Insurrancedata/train.csv", col_types = cols())
dim_data_train <- dim(data_train)
print(paste0("Le jeu de données contient ", dim_data_train[1],
" observations pour ", dim_data_train[2], " variables"))
dist_target <- table(data_train$target)
perc_claim <- paste0(round((dist_target[2]/dist_target[1]) *100, 2), "%",
" des clients dans le jeu de données ont fait une réclamation.")
ggplot2::ggplot(data = data_train, aes(x = as.factor(target))) +
geom_bar(fill = "#84a5a3") + labs(title = "Distribution de la class Target",
x = "Réclamation", y = "Fréquence", subtitle= perc_claim) + scale_y_continuous(labels = scales::comma)
vars_cat <- names(data_train)[grepl("_cat$", names(data_train))]
data_train <- data_train %>% mutate_at(.vars = vars_cat, .funs = as.factor)
data_train <- model.matrix(~. – 1, data = data_train)
data_train <- as.data.frame(data_train)
res <- stats::prcomp(data_train[, c(-1, -2)], center = TRUE, scale = TRUE)
data_train_transformed <- data.frame(target = data_train$target, res$x)
.Deprecated("loadModule", package = "RSofia", old = "loadRcppModules")
require(RSofia)
# pour faire les parallèles et le loop des fold
require(doParallel)
require(foreach)
gc()
### Échantilllonnage à 70/30
split_size <- floor(0.7 * nrow(data_train_transformed))
set.seed(122)
train_index <- caret::createDataPartition(data_train_transformed$target, p = 0.7, list = FALSE, times = 1)
train_70 <- data_train_transformed[train_index, ]
test_30 <- data_train_transformed[-train_index, ]
## K FOLD VALIDATION Préparation Définir le nombre cores pour
## le k fold validation
registerDoParallel(cores = 10)
### Identifier les folds dans le jeu de données/ Nb de
### cores==Nb de fold — Ici 10 cores pour 10 fold
set.seed(117)
train_70$fold <- caret::createFolds(train_70$target, k = 10, list = FALSE)
### Pegasos et SVM avec K-FOLD VALIDATION
output_cv <- foreach::foreach(j = 1:max(train_70$fold), .combine = rbind,.inorder = TRUE) %dopar% {
cv_train <- train_70[train_70$fold != j, ]
cv_test <- train_70[train_70$fold == j, ]
### Sofia ml package pour 10 millions d’itération, un lambda à
### 0.01 et un échantillonnage d’itération pour optimiser la
### AUC ROC.
svm_pegasos <- RSofia::sofia(target ~ ., data = cv_train,
random_seed = 201, lambda = 0.01, iterations = 1e+07,
learner_type = "pegasos", eta_type = "pegasos", loop_type = "roc",
training_objective = FALSE, verbose = FALSE)
svm_pegasos_validation <- predict.sofia(svm_pegasos, cv_test,
prediction_type = "logistic")
gini <- NormalizedGini(svm_pegasos_validation, cv_test$target)
result <- data.frame(y = cv_test$target, prob = svm_pegasos_validation)
list(svm_pegasos = svm_pegasos, gini = gini, result = result)
}
gc()
paste0(mean(output_cv$gini), "Gini coeff moyen durant la validation avec 10 folds")
svm_pegasos_test <- predict.sofia(output_cv$svm_pegasos, test_30,
prediction_type = "logistic")
paste0(NormalizedGini(svm_pegasos_test, test_30$target), "Gini coeff pour la phase test")
svm_pegasos_test_threshold <- ifelse(svm_pegasos_test < 0.6,0, 1)
ConfusionMatrix(svm_pegasos_test_threshold, test_30$target)
[/sourcecode]
CONCLUSION
Notre modèle présente des résultats de validation et de test convenables. Cependant, il faut garder en tête que notre modèle présente un nombre non négligeable de faux positif. À la lumière de nos observations, il ne reste plus qu’à soumettre le résultat aux données fournies par Kaggle. Afin de raffiner et d’améliorer le modèle, sachez que d’autres solveurs pourraient être utilisés. Il est également possible d’essayer des techniques d’échantillonnages.
RÉFÉRENCES
https://www.kaggle.com/bertcarremans/data-preparation-exploration
https://github.com/cran/RSofia
https://stats.stackexchange.com/questions/186924/cascade-svm-in-r
Practical Guide to Principal Component Analysis (PCA) in R & Python
https://www.youtube.com/watch?v=8syQKTdgdzc
https://stackoverflow.com/questions/32588149/train-svm-on-a-very-large-dataset-stored-on-hard-drive
Understanding Support Vector Machine algorithm from examples (along with code)
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/34638.pdf

{kind=link}